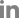ņä£ļĪĀ
ņØśļŻī ļČäņĢ╝ņŚÉņä£ ņĀĢļ░ĆņØśļŻīļŖö ļŗ╣ļć©ļ│æĻ│╝ Ļ░ÖņØĆ ļ¦īņä▒ļīĆņé¼ņ¦łĒÖśņŚÉ ļīĆĒĢ£ ņĀæĻĘ╝ ļ░®ņŗØņØä ĒśüņŗĀņĀüņ£╝ļĪ£ ļ│ĆĒÖöņŗ£ĒéżĻ│Ā ņ׳ļŗż. ņØ┤ ļ│ĆĒÖö ņżæ ņāüļŗ╣ ļČĆļČäņØĆ ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼ļź╝ ĒåĄĒĢ┤ņä£ ņØ┤ļŻ©ņ¢┤ņ¦ĆĻ│Ā ņ׳ņ£╝ļ®░ ņØ┤ņĀäņŚÉļŖö Ļ░¢ĻĖ░ ņ¢┤ļĀżņøĀļŹś ĒåĄņ░░ļĀźņØä ņĀ£Ļ│ĄĒĢśĻ│Ā ņ׳ļŗż. ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼ļŖö ņØĖņóģļ│äļĪ£ ņ¢┤ļ¢╗Ļ▓ī ļŗ╣ļć©ļ│æņØ┤ ļŗżļź┤Ļ▓ī ļéśĒāĆļéśļŖöņ¦Ć, ĻĘĖļ”¼Ļ│Ā Ļ░£ņØĖļ│ä ņ░©ņØ┤Ļ░Ć ņÖ£ ļ░£ņāØĒĢśļŖöņ¦ĆņŚÉ ļīĆĒĢ£ ņØ┤ņ¦łņä▒ņØä ņØ┤ĒĢ┤ĒĢśĻĖ░ ņ£äĒĢ£ ĻĖ┤ ņŚ¼ņĀĢņØś ņŗ£ņ×æņĀÉņ£╝ļĪ£ ņŚ¼Ļ▓©ņ¦äļŗż. ĒĢśņ¦Ćļ¦ī ņØ┤ļ¤¼ĒĢ£ ļŗ╣ļć©ļ│æ ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼Ļ░Ć ņŗżņĀ£ ņ¦äļŻīņŚÉ ņ¢┤ļ¢╗Ļ▓ī ĒÖ£ņÜ®ļÉĀ Ļ▓āņØĖņ¦ĆļŖö ņĢäņ¦ü ļ¬ģĒÖĢĒĢśņ¦Ć ņĢŖļŗż. Ēśäņ×¼ ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼ Ļ▓░Ļ│╝Ļ░Ć ņ×äņāü ņ¦äļŻīņŚÉ ĒÖ£ņÜ®ļÉĀ Ļ░ĆļŖźņä▒ņØĆ ņ£ĀņĀäņ£äĒŚśņĀÉņłś(polygenic risk score)ļź╝ ĒåĄĒĢ┤ņä£ņØ╝ Ļ░ĆļŖźņä▒ņØ┤ ļåÆļŗż.
ļ│ĖļĪĀ
1. ļŗ╣ļć©ļ│æ ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼ņØś ņŚģļŹ░ņØ┤ĒŖĖ
ņĄ£ĻĘ╝ ļŗ╣ļć©ļ│æ ņŚ░ĻĄ¼ ļ░Å ņ¦äļŻīņØś ĒÖöļæÉ ņżæ ĒĢśļéśĻ░Ć ņĀĢļ░ĆņØśļŻīņØ┤ļŗż. ļ»ĖĻĄŁļŗ╣ļć©ļ│æĒĢÖĒÜīņÖĆ ņ£Āļ¤Įļŗ╣ļć©ļ│æĒĢÖĒÜīņŚÉņä£ ļŗ╣ļć©ļ│æ ņĀĢļ░ĆņØśļŻī ņØ┤ļŗłņģöĒŗ░ļĖī(Precision Medicine in Diabetes Initiative)ļź╝ ĻĄ¼ņä▒ĒĢśņŚ¼ ņĀĢļ░ĆņØśļŻīĻ░Ć ņ¢┤ļ¢╗Ļ▓ī ļŗ╣ļć©ļ│æņØś ņŚ░ĻĄ¼ņÖĆ ņ¦äļŻīļź╝ ļ░öĻŠĖĻ▓ī ļÉĀ Ļ▓āņØĖņ¦Ć ļ│┤Ļ│Āņä£ļź╝ ļ░£Ēæ£ĒĢ£ ļ░ö ņ׳ļŗż. ņś¼ĒĢ┤ 10ņøöņŚÉ ļ░£Ēæ£ļÉ£ 2ņ░© ļ│┤Ļ│Āņä£[1]ņŚÉ ļö░ļź┤ļ®┤ ņĢäņ¦üĻ╣īņ¦Ć ļŗ╣ļć©ļ│æņØś ņØ┤ņ¦łņä▒ņØś ņøÉņØĖĻ│╝ ņØ┤ņŚÉ ļ¦×ņČś ņ╣śļŻīņĀäļץņŚÉ ļīĆĒĢ£ ņŚ░ĻĄ¼ļŖö ļ¦ÄņØ┤ ļČĆņĪ▒ĒĢ£ ĒÄĖņØ┤ļŗż. ļśÉĒĢ£ ņØ┤ ļ│┤Ļ│Āņä£ļŖö Ēśäņ×¼Ļ╣īņ¦Ć ņśżļ»╣ņŖż ņŚ░ĻĄ¼ ļō▒ņØä ĒåĄĒĢ┤ ĻĘ£ļ¬ģļÉ£ ņāłļĪ£ņÜ┤ ņ£äĒŚśņØĖņ×ÉļōżņØ┤ ņ¢┤ļ¢╗Ļ▓ī ņ¦äļŻī ĒśäņןņŚÉ ĒÖ£ņÜ®ļÉĀ ņłś ņ׳ņØä Ļ▓āņØĖņ¦ĆņŚÉ ļīĆĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ļ│┤ļŗż ļ¦ÄņØ┤ ĒĢäņÜöĒĢ©ņØä Ļ░ĢņĪ░ĒĢśĻ│Ā ņ׳ļŗż.
ļŗ╣ļć©ļ│æ ņĀäņןņ£ĀņĀäņ▓┤ņŚ░Ļ┤Ćņä▒ņŚ░ĻĄ¼(genome-wide association study)ļŖö ņ¦ĆņåŹņĀüņ£╝ļĪ£ ĻĘĖ ĻĘ£ļ¬©Ļ░Ć ņ╗żņĀĖņä£ ņØ┤ļ»Ė ņłśļģä ņĀä 100ļ¦ī ļ¬ģ ņØ┤ņāüņØś ļīĆņāüņ×Éļź╝ ĒżĒĢ©ĒĢśņśĆĻ│Ā, 5ļīĆ ņØĖņóģņØä ļ¬©ļæÉ ĒżĒĢ©ĒĢśņŚ¼ ņ£ĀņĀäņĀü ņ░©ņØ┤ņØś ĒÜ©Ļ│╝ļź╝ ļ│┤Ļ│Āņ×É ĒĢśļŖö ļ░®Ē¢źņ£╝ļĪ£ ņ¦äĒ¢ēļÉśĻ│Ā ņ׳ļŗż. ņś¼ĒĢ┤ ņ¦äĒ¢ēļÉśĻ│Ā ņ׳ļŖö ņŻ╝ļ¬®ĒĢĀ ļ¦īĒĢ£ ņŚ░ĻĄ¼ļĪ£ Suzuki ņÖĆ ĻĘĖņØś ĒīĆņØ┤ ņłśĒ¢ēĒĢ£ ņĀäņןņ£ĀņĀäņ▓┤ņŚ░Ļ┤Ćņä▒ņŚ░ĻĄ¼Ļ░Ć ņ׳ļŖöļŹ░, Ēśäņ×¼ medRxivņŚÉ Ēöäļ”¼Ēöäļ”░ĒŖĖ(preprint)ļĪ£ ļ░£Ēæ£ļÉśņŚłņ£╝ļ®░ Nature ņŚÉņä£ ņŗ¼ņé¼ ņżæņØ┤ļŗż[2]. ņØ┤ ņŚ░ĻĄ¼ļŖö 250ļ¦ī ļ¬ģ ņØ┤ņāüņØś ņ░ĖĻ░Ćņ×Éļź╝ ļČäņäØĒĢśņŚ¼ 2ĒśĢļŗ╣ļć©ļ│æ Ļ┤ĆļĀ© 611Ļ░£ņØś ņ£ĀņĀäņ×Éļ│ĆņØ┤ļź╝ ĒÖĢņØĖĒĢśņśĆļŗż. ņØ┤ ņŚ░ĻĄ¼ļŖö 2ĒśĢļŗ╣ļć©ļ│æ ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼ļĪ£ļŖö ņĄ£ļīĆ ĻĘ£ļ¬©ņØ┤ļ®░ ņØĖņóģņĀü ņ░©ņØ┤Ļ░Ć ņ¢┤ļ¢╗Ļ▓ī ļŗ╣ļć©ļ│æ ņ£äĒŚś ļ░Å ĒŖ╣ņä▒ņŚÉ Ļ┤ĆļĀ©ļÉśļŖöņ¦Ć ļ│┤ņŚ¼ņŻ╝Ļ│Ā ņ׳ļŗż. ņØ┤ļŖö ĻĘ£ļ¬© ļ░Å Ļ▓░Ļ│╝ņØś ņĖĪļ®┤ņŚÉņä£ ņżæņÜöĒĢ£ Ļ│╝ĒĢÖņĀü ņä▒Ļ│╝ņØ╝ ļ┐Éļ¦ī ņĢäļŗłļØ╝ ņØĖņóģļ│ä, Ļ░£ņØĖļ│ä ņ£ĀņĀäņĀü ņ░©ņØ┤Ļ░Ć ņ¢┤ļ¢╗Ļ▓ī ļŗ╣ļć©ļ│æņŚÉ ņśüĒ¢źņØä ļ»Ėņ╣śļŖöņ¦Ć ņĀĢļ░ĆņØśļŻīņØś ņżæņÜöĒĢ£ ņ¦ĆņŗØ ĻĖ░ļ░śņØä ņĀ£Ļ│ĄĒĢśĻ│Ā ņ׳ļŗżļŖö ņĀÉņŚÉņä£ ņØśņØśĻ░Ć ņ׳ļŗż. ĒŖ╣Ē׳ ļŗżņ¢æĒĢ£ ņØĖņóģņŚÉņä£ ņ£ĀņĀäņ£äĒŚśņĀÉņłś Ļ│äņé░ņØä ņ£äĒĢ£ ņŻ╝ņÜö ļ│ĆņØ┤ ļ¬®ļĪØĻ│╝ Ļ░ü ļ│ĆņØ┤ņØś Ļ░Ćņżæņ╣śļź╝ ņĀ£Ļ│ĄĒĢśĻ│Ā ņ׳ļŗż.
2. ņ£ĀņĀäņ£äĒŚśņĀÉņłśņØś Ļ░£ļģÉĻ│╝ Ļ│äņé░
ņ£ĀņĀäņ£äĒŚśņĀÉņłśļŖö ļŗ╣ļć©ļ│æ Ļ░ÖņØĆ ĒŖ╣ņĀĢ ņ¦łļ│æņØ┤ļéś Ļ│Ąļ│ĄĒśłļŗ╣Ļ│╝ Ļ░ÖņØĆ ĒśĢņ¦łņŚÉ ļīĆĒĢ£ ņ£ĀņĀäņĀü ņ£äĒŚśņØä ļéśĒāĆļé┤ļŖö Ļ▓āņ£╝ļĪ£, Ļ░£ņØĖļ│äļĪ£ ņłśņŗŁ Ļ░£ Ēś╣ņØĆ ņłśļ░▒ Ļ░£ ņØ┤ņāüņØś ĒØöĒĢ£ ņ£ĀņĀäņĀü ļ│ĆņØ┤ļź╝ ĒÖĢņØĖĒĢśĻ│Ā Ļ░ü ļ│ĆņØ┤ņŚÉ ļīĆĒĢ£ Ļ░Ćņżæņ╣śļź╝ ņĀüņÜ®ĒĢśņŚ¼ ĻĘĖ ņ┤ØĒĢ®ņØä Ļ│äņé░ĒĢ┤ ļéśĒāĆļé┤ļŖö ņĀÉņłśņØ┤ļŗż. ļŗ╣ļć©ļ│æ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļź╝ Ļ│äņé░ĒĢśĻĖ░ ņ£äĒĢ┤ņä£ļŖö Ļ│äņé░ņŚÉ ĒżĒĢ©ļÉĀ ļŗ╣ļć©ļ│æ Ļ┤ĆļĀ© ņ£ĀņĀäņ×Éļ│ĆņØ┤ļź╝ ļ»Ėļ”¼ ņäĀņĀĢĒĢśļŖö Ļ▓āņØ┤ ĒĢäņÜöĒĢ£ļŹ░, ņØ┤ļŖö ļīĆĻ░£ ĻĖ░ņĪ┤ņŚÉ ļ│┤Ļ│ĀļÉ£ ņĀäņןņ£ĀņĀäņ▓┤ņŚ░Ļ┤Ćņä▒ņŚ░ĻĄ¼ Ļ▓░Ļ│╝ļź╝ ņØ┤ņÜ®ĒĢ£ļŗż. ļīĆļČĆļČäņØś ņĀäņןņ£ĀņĀäņ▓┤ņŚ░Ļ┤Ćņä▒ņŚ░ĻĄ¼ļōżņØĆ ņ¢┤ļ¢ż ļ│ĆņØ┤Ļ░Ć ņ£ĀņØśĒĢśĻ▓ī ļŗ╣ļć©ļ│æĻ│╝ Ļ┤ĆļĀ©ņØ┤ ņ׳ļŖöņ¦Ć, ĻĘĖļ”¼Ļ│Ā Ļ░ü ļīĆļ”Įņ£ĀņĀäņ×ÉĻ░Ć ņ¢┤ļŖÉ ņĀĢļÅäņØś Ļ░Ćņżæņ╣śļĪ£ ļŗ╣ļć©ļ│æņØś ņ£äĒŚśņØä ņ”ØĻ░Ćņŗ£ĒéżļŖöņ¦Ć ņÜöņĢĮ Ļ░Æņ£╝ļĪ£ ņĀ£Ļ│ĄĒĢśĻ│Ā ņ׳ļŗż. ņ£ĀņĀäņ£äĒŚśņĀÉņłśņŚÉ ņé¼ņÜ®ļÉĀ ņÜöņĢĮ Ļ░ÆļōżņØä ņĀĢļ”¼ĒĢ┤ ļåōņØĆ ņø╣ņé¼ņØ┤ĒŖĖļź╝ ĒÖ£ņÜ®ĒĢśļŖö Ļ▓āļÅä Ļ░ĆļŖźĒĢśļŗż(https://www.pgscatalog.org/). ņĀäņןņ£ĀņĀäņ▓┤ņŚ░Ļ┤Ćņä▒ņŚ░ĻĄ¼ļōż ņżæ ļ│ĖņØĖņØ┤ ņĀüņÜ®ĒĢśĻ│Āņ×É ĒĢśļŖö ņØĖĻĄ¼ņ¦æļŗ©Ļ│╝ ņØĖņóģņØ┤ Ļ░Ćņן ņ£Āņé¼ĒĢśļ®░ ĻĘ£ļ¬©Ļ░Ć Ēü░ ņŚ░ĻĄ¼ļź╝ ņäĀĒāØĒĢśļŖö Ļ▓āņØ┤ ņżæņÜöĒĢśļŗż. ņØ┤Ēøä ņĀüņÜ®ļÉĀ ļīĆņāüņ¦æļŗ©ņØś ņ£ĀņĀäĒśĢņØä ļČäņäØ Ēøä ņ£ĀņĀäĒśĢņŚÉ ļö░ļØ╝ Ļ░Ćņżæņ╣śļź╝ ņĀüņÜ®ĒĢśņŚ¼ ņ┤ØĒĢ®ņØä Ļ│äņé░ĒĢśļ®┤ ļÉ£ļŗż. ņŗżņĀ£ ņĀäņ▓┤ ĒĢ®ņØä ĻĄ¼ĒĢśļŖö ļ░®ņŗØņØĆ ņ£ĀņØśĒĢ£ ļ│ĆņØ┤ļ¦ī ĒżĒĢ©ĒĢĀņ¦Ć, ņĢäļŗłļ®┤ ņ£ĀņØśĒĢśņ¦Ć ņĢŖļŹöļØ╝ļÅä ņĀäņ▓┤ ņ£ĀņĀäņ▓┤ ņĀĢļ│┤ļź╝ ļ¬©ļæÉ ĒżĒĢ©ĒĢĀņ¦Ć ļō▒ņŚÉ ļö░ļØ╝ ļŗżļź╝ ņłś ņ׳ļŗż. ņĄ£ĻĘ╝ņŚÉļŖö ņĀäņ▓┤ ņ£ĀņĀäņ×Éļ│ĆņØ┤ ņĀĢļ│┤ļź╝ ĒÖ£ņÜ®ĒĢśļŖö LDpred, PRS-CS (polygenic risk score-continuous shrinkage) ļō▒ņØś ļ░®ļ▓ĢņØ┤ ļäÉļ”¼ ņé¼ņÜ®ļÉśĻ│Ā ņ׳ļŗż[3].
3. ļŗ╣ļć©ļ│æ ņ£ĀņĀäņ£äĒŚśņĀÉņłśņØś ņ×äņāü ĒÖ£ņÜ®
ļŗ╣ļć©ļ│æ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļŖö (1) ļŗ╣ļć©ļ│æņŚÉ ņØ┤ĒÖśļÉĀ ņé¼ļ×īļōżņØä ļ»Ėļ”¼ ņśłņĖĪĒĢśļŖö ļŹ░ ņé¼ņÜ®ļÉśĻ│Ā (2) ļŗ╣ļć©ļ│æņØś ņĢäĒśĢ ļČäļźś ļ░Å (3) ļŗ╣ļć©ļ│æ ņ£äĒŚśļÅä ņ×¼ļČäļźś ļō▒ņŚÉ ĒÖ£ņÜ®ļÉĀ Ļ░ĆļŖźņä▒ņØ┤ ņ׳ļŗż. ļŗ╣ļć©ļ│æņØ┤ ņŚåļŖö ņé¼ļ×īņŚÉ ļ╣äĒĢ┤ ļŗ╣ļć©ļ│æņØ┤ ļ░£ļ│æĒĢśļŖö ņé¼ļ×īņØĆ ņ£ĀņĀäņ£äĒŚśņĀÉņłśĻ░Ć ņ£ĀņØśĒĢśĻ▓ī ļåÆņØĆ Ļ▓āņØ┤ ņל ņĢīļĀżņĀĖ ņ׳ļŗż. ņ┤łĻĖ░ 2ĒśĢļŗ╣ļć©ļ│æ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļŖö ĒżĒĢ©ļÉśļŖö ņ£ĀņĀäņ×Éļ│ĆņØ┤ņØś ņłśĻ░Ć ņłśņŗŁ Ļ░£ ņĀĢļÅäļĪ£ ņĀüĻ│Ā Ļ│äņé░ ļ░®ņŗØļÅä ļŗ©ņł£ĒĢśņśĆĻĖ░ ļĢīļ¼ĖņŚÉ ļŗ╣ļć©ļ│æņØ┤ ļ░£ņāØĒĢśļŖö ĻĄ░Ļ│╝ ĻĘĖļĀćņ¦Ć ņĢŖņØĆ ĻĄ░ņŚÉņä£ ņĀÉņłś ņ░©ņØ┤Ļ░Ć Ēü¼ņ¦Ć ņĢŖņĢśĻ│Ā ņśłņĖĪļĀźļÅä ļåÆņ¦Ć ņĢŖņĢśļŗż. ĒĢśņ¦Ćļ¦ī ņĄ£ĻĘ╝ ņłśļ░▒ Ļ░£ ņØ┤ņāüņØś 2ĒśĢļŗ╣ļć©ļ│æ ņ£ĀņĀäņ×Éļ│ĆņØ┤Ļ░Ć ņ£ĀņØśĒĢ£ ļ│ĆņØ┤ļĪ£ ņäĀņĀĢļÉśĻ│Ā ņĀäņ▓┤ ņ£ĀņĀäņ▓┤ ņĀĢļ│┤ļź╝ ĒÖ£ņÜ®ĒĢśļŖö Ļ│äņé░ļ▓Ģ ļō▒ņØ┤ ļō▒ņןĒĢśļ®┤ņä£ ļŗ╣ļć©ļ│æ ņ£ĀņĀäņ£äĒŚśņĀÉņłśņØś ņśłņĖĪļĀźņØ┤ ļŹö ņ”ØĻ░ĆĒĢśĻ│Ā ņ׳ļŗż. ļśÉĒĢ£ ņ£ĀņĀäņ£äĒŚśņĀÉņłś ņāüņ£ä 10% Ļ░ÆņØä Ļ░¢ļŖö ņé¼ļ×īļōżņØĆ ļéśļ©Ėņ¦Ć 90%ņŚÉ ļ╣äĒĢśņŚ¼ ļŗ╣ļć©ļ│æņØś ņ£äĒŚśņØ┤ 2Ōł╝3ļ░░ ņØ┤ņāü ļåÆņØĆ Ļ▓āņ£╝ļĪ£ ļéśĒāĆļéśņä£ ņØ┤ļōżņØä Ļ│Āņ£äĒŚśĻĄ░ņ£╝ļĪ£ ņäĀļ│äĒĢśļŖö Ļ▓āņØ┤ ņĀ£ņĢłļÉśĻ│Ā ņ׳ļŗż[4]. ņØ┤ļōżņŚÉ ļīĆĒĢ┤ ņ¦æņżæņĀüņ£╝ļĪ£ ņäĀļ│äĻ▓Ćņé¼ļź╝ ņŗ£Ē¢ēĒĢśĻ│Ā ņśłļ░® ņżæņ×¼ļź╝ ĒĢśļŖö Ļ▓āņØ┤ ņóŗņØĆ ņĀäļץņ£╝ļĪ£ ņĀ£ņŗ£ļÉśĻ│Ā ņ׳ņ£╝ļéś ņØ┤ņŚÉ ļīĆĒĢ┤ņä£ļŖö ņČöĻ░ĆņĀüņØĖ ņĀäĒ¢źņĀü ņŚ░ĻĄ¼Ļ░Ć ĒĢäņÜöĒĢśļŗż.
ļŗ╣ļć©ļ│æ ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼ Ļ▓░Ļ│╝ ļ░Å ņ£ĀņĀäņ£äĒŚśņĀÉņłśļŖö ņ×äņŗĀļŗ╣ļć©ļ│æ, ņŗĀņāØņĢä ļŗ╣ļć©ļ│æ, ļŗ©ņØ╝ņ£ĀņĀäņ×É ļŗ╣ļć©ļ│æ, 1ĒśĢļŗ╣ļć©ļ│æ, 2ĒśĢļŗ╣ļć©ļ│æ, ļŗ╣ļć©ļ│æņØś ĒĢ®ļ│æņ”Ø ļō▒ ļŗżņ¢æĒĢ£ ļČäņĢ╝ņØś ņ¦äļŻīņŚÉ ļ¬©ļæÉ ņĀüņÜ®ņØ┤ ļÉĀ ņłś ņ׳ļŗż(Fig. 1). ņ£ĀņĀäņ£äĒŚśņĀÉņłśĻ░Ć ļŗ╣ļć©ļ│æņØś Ļ░ü ņĢäĒśĢņŚÉ ņ¢┤ļ¢╗Ļ▓ī ņāüņÜ®ļÉĀ ņłś ņ׳ļŖöņ¦Ćļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤ ļŗżņØīĻ│╝ Ļ░Öļŗż.
Fig.┬Ā1.
The results of genetic studies and polygenic risk scores for diabetes can be applied to a wide range of clinical areas, including gestational diabetes, neonatal diabetes, monogenic diabetes, type 1 diabetes, type 2 diabetes, and complications of diabetes.

1) 1ĒśĢļŗ╣ļć©ļ│æ
1ĒśĢļŗ╣ļć©ļ│æņØĆ 2ĒśĢļŗ╣ļć©ļ│æņŚÉ ļ╣äĒĢśņŚ¼ ņ£ĀņĀäņä▒ņØ┤ ļåÆņØĆ Ļ▓āņ£╝ļĪ£ ņĢīļĀżņĀĖ ņ׳ļŗż. ļīĆļČĆļČäņØś ņ£ĀņĀäņä▒ņØĆ ņé¼ļ×īļ░▒ĒśłĻĄ¼ĒĢŁņøÉ(human leu-kocyte antigen, HLA) ņ£ĀņĀäĒśĢņŚÉ ļö░ļØ╝ Ļ▓░ņĀĢļÉśļ®░ ņØ╝ļČĆ HLA ņØ┤ņÖĖ ņ£ĀņĀäĒśĢļÅä 1ĒśĢļŗ╣ļć©ļ│æņØś ņ£äĒŚśņŚÉ ĻĖ░ņŚ¼ĒĢ£ļŗż. HLA ņ£ĀņĀäĒśĢņØä ĒżĒĢ©ĒĢśņŚ¼ 1ĒśĢļŗ╣ļć©ļ│æ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļź╝ Ļ│äņé░ĒĢśļ®┤ 1ĒśĢļŗ╣ļć©ļ│æņØä ņל ņśłņĖĪĒĢĀ ņłś ņ׳ļŗż. ņØ┤ļŖö ĒŖ╣Ē׳ ņåīņĢäņ▓ŁņåīļģäņŚÉņä£ ļ░£ņāØĒĢ£ ļŗ╣ļć©ļ│æņØ┤ 1ĒśĢļŗ╣ļć©ļ│æņØĖņ¦Ć, ļŗ©ņØ╝ņ£ĀņĀäņ×Éļ│ĆņØ┤ņŚÉ ņØśĒĢ£ ļŗ╣ļć©ļ│æņØĆ ņĢäļŗīņ¦Ć, 2ĒśĢļŗ╣ļć©ļ│æņØĆ ņĢäļŗīņ¦Ć ļō▒ ļŗ╣ļć©ļ│æņØś ļČäļźśņŚÉ ņé¼ņÜ®ļÉĀ ņłś ņ׳ļŗż[5]. ļśÉĒĢ£ ĒÖśņ×ÉņØś ĒśĢņĀ£ ļō▒ ņ¦üĻ│ä Ļ░ĆņĪ▒ņŚÉņä£ 1ĒśĢļŗ╣ļć©ļ│æņØś ņ£äĒŚśņØä ņśłņĖĪĒĢśļŖö ļŹ░ļÅä ĒÖ£ņÜ®ļÉĀ ņłś ņ׳ļŗż.
2) ļŗ©ņØ╝ņ£ĀņĀäņ×Éļ│ĆņØ┤ņŚÉ ņØśĒĢ£ ļŗ╣ļć©ļ│æ
ļŗ©ņØ╝ņ£ĀņĀäņ×Éļ│ĆņØ┤ņŚÉ ņØśĒĢ£ ļŗ╣ļć©ļ│æņØĆ ņŚ╝ĻĖ░ņä£ņŚ┤ļČäņäØļ▓ĢņŚÉ ņØśĒĢ┤ ņ¦äļŗ©ņØ┤ Ļ░ĆļŖźĒĢśļŗż. ĒĢśņ¦Ćļ¦ī ņĢäņ¦üĻ╣īņ¦Ć ņŚ╝ĻĖ░ņä£ņŚ┤ļČäņäØļ▓ĢņØĆ ļ╣äņÜ®ņØ┤ Ļ│ĀĻ░ĆņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ Ļ▓Ćņé¼ļź╝ ņŗ£Ē¢ēĒĢĀ ņé¼ļ×īļōżņØä ņäĀļ│äĒĢśļŖö Ļ▓āņØ┤ ĒĢäņÜöĒĢśļŗż. ņØ┤ Ļ│╝ņĀĢņŚÉņä£ 2ĒśĢļŗ╣ļć©ļ│æ Ēś╣ņØĆ 1ĒśĢļŗ╣ļć©ļ│æņØś ņ£ĀņĀäņ£äĒŚśņĀÉņłśĻ░Ć ļé«ņØĆ ņé¼ļ×īļōżņØ┤ ņāüļīĆņĀüņ£╝ļĪ£ ļŗ©ņØ╝ņ£ĀņĀäņ×Éļ│ĆņØ┤ņØś Ļ░ĆļŖźņä▒ņØ┤ ļåÆņØä Ļ▓āņØ┤ļŗż. ļö░ļØ╝ņä£ ņŚ╝ĻĖ░ņä£ņŚ┤ļČäņäØļ▓ĢņØä ņŗ£Ē¢ēĒĢĀ ņé¼ļ×īļōżņØä ņäĀļ│äĒĢśļŖö ļŹ░ņŚÉ ņ£ĀņĀäņ£äĒŚśņĀÉņłśĻ░Ć ņé¼ņÜ®ļÉĀ ņłś ņ׳ļŗż.
3) ņ×äņŗĀļŗ╣ļć©ļ│æ
ņ×äņŗĀļŗ╣ļć©ļ│æņØĆ ņ×äņŗĀ ņĀä Ēś╣ņØĆ ņ×äņŗĀ ņ┤łĻĖ░ņŚÉ ņ×äņāüņĀü ņ¦ĆĒæ£ļ¦īņ£╝ļĪ£ ļ»Ėļ”¼ ņśłņĖĪĒĢśĻĖ░Ļ░Ć ņ¢┤ļĀĄļŗż. ļö░ļØ╝ņä£ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļĪ£ ņ×äņŗĀļŗ╣ļć©ļ│æņØä ņśłņĖĪĒĢśļĀżļŖö ņŗ£ļÅäļōżņØ┤ ņ׳ņ£╝ļéś ņĢäņ¦üĻ╣īņ¦Ć ļ¦ÄņØĆ ņŚ░ĻĄ¼ļōżņØ┤ ņ¦äĒ¢ēļÉśņ¦ĆļŖö ņĢŖņĢśļŗż. ņØ┤ļŖö ņ×äņŗĀļŗ╣ļć©ļ│æ Ļ┤ĆļĀ© ļīĆĻĘ£ļ¬© ņ£ĀņĀäņ▓┤ ņŚ░ĻĄ¼ļōżņØ┤ ļ¦Äņ¦Ć ņĢŖĻĖ░ ļĢīļ¼ĖņŚÉ ņ×äņŗĀļŗ╣ļć©ļ│æņŚÉ ĒŖ╣ĒÖöļÉ£ ņ£ĀņĀäņ£äĒŚśņĀÉņłś Ļ░£ļ░£ņØ┤ ņĀ£ĒĢ£ņĀüņØ┤ĻĖ░ ļĢīļ¼ĖņØ┤ļŗż. ļīĆņŗĀņŚÉ ņ×äņŗĀļŗ╣ļć©ļ│æĻ│╝ 2ĒśĢļŗ╣ļć©ļ│æņØ┤ ņ£ĀņĀäņĀü ņ£äĒŚś ņÜöņØĖņØ┤ ļ╣äņŖĘĒĢśļŗżļŖö ņĀÉņŚÉ ņ░®ņĢłĒĢśņŚ¼ 2ĒśĢļŗ╣ļć©ļ│æņØä ņØ┤ņÜ®ĒĢśņŚ¼ ņ×äņŗĀļŗ╣ļć©ļ│æņØä ņśłņĖĪĒĢśļĀżļŖö ņŗ£ļÅäļōżņØ┤ ņ׳ļŗż. ļśÉĒĢ£ ņ×äņŗĀļŗ╣ļć©ļ│æ ņØ┤Ēøä 2ĒśĢļŗ╣ļć©ļ│æ ņśłņĖĪĻ│╝ Ļ┤ĆļĀ©ļÉ£ ņ£ĀņĀäņ£äĒŚśņĀÉņłśņØś ņ×äņāüņĀü ĒÖ£ņÜ®ņŚÉ ļīĆĒĢ£ ņŚ░ĻĄ¼ļōżļÅä ĒÖ£ļ░£Ē׳ ņ¦äĒ¢ēļÉśĻ│Ā ņ׳ļŗż[6].
4) 2ĒśĢļŗ╣ļć©ļ│æ
ņ£ĀņĀäņ£äĒŚśņĀÉņłśĻ░Ć 2ĒśĢļŗ╣ļć©ļ│æņØä ņśłņĖĪĒĢ£ļŗżļŖö Ļ▓āņØĆ ļ╣äĻĄÉņĀü ņל ņ”Øļ¬ģļÉśņŚłļŗż. ĒĢśņ¦Ćļ¦ī ņ£ĀņĀäņ£äĒŚśņĀÉņłśĻ░Ć Ļ│Ąļ│ĄĒśłļŗ╣, Ēś╣ņØĆ ļŗ╣ĒÖöĒśłņāēņåī Ļ░ÖņØ┤ ņ¦äļŗ©ņŚÉ ņ¦üņĀæņĀüņ£╝ļĪ£ ņé¼ņÜ®ļÉśļŖö ņ¦ĆĒæ£ļ│┤ļŗż ņśłņĖĪļĀźņØ┤ ļåÆņØä ņłśļŖö ņŚåļŗż. ļö░ļØ╝ņä£ 40Ōł╝50ļīĆ ņØ┤ņĀä Ēśłļŗ╣ņØ┤ ļåÆņĢäņ¦ĆĻĖ░ ņØ┤ņĀäņŚÉ ĻĘĖ ņ×äņāüņĀü ņ£ĀņÜ®ņä▒ņØ┤ ļŹö ļåÆņØä Ļ▓āņ£╝ļĪ£ ņāØĻ░üļÉ£ļŗż.
ĻĘĖ ņÖĖņŚÉ 2ĒśĢļŗ╣ļć©ļ│æņØś ņäĖļČĆ ļČäļźśļź╝ ņ£äĒĢ┤ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļź╝ ņØ┤ņÜ®ĒĢśĻ│Āņ×É ĒĢśļŖö ņŚ░ĻĄ¼ļÅä ĒÖ£ļ░£Ē׳ ņ¦äĒ¢ē ņżæņØ┤ļŗż[7]. ņØĖņŖÉļ”░ ļČäļ╣ä, ņØĖņŖÉļ”░ņĀĆĒĢŁņä▒, ļ╣äļ¦ī ļō▒ ļŗ╣ļć©ļ│æņØś ņŚ¼ļ¤¼ ļ│æĒā£ĻĖ░ņĀä Ļ▓ĮļĪ£ņŚÉ ļö░ļźĖ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļź╝ ĻĄ¼ņä▒ĒĢśĻ│Ā Ļ░üĻ░üņØś ņĀÉņłśņŚÉ ļö░ļØ╝ 2ĒśĢļŗ╣ļć©ļ│æņØä ņäĖļČĆ ļČäļźśĒĢśļĀżļŖö ņŚ░ĻĄ¼ļōżņØ┤ ļ░£Ēæ£ļÉ£ ļ░ö ņ׳ļŗż. ĒĢśņ¦Ćļ¦ī ņØ┤ļ¤¼ĒĢ£ ņŚ░ĻĄ¼ļŖö ļŗżļźĖ ņØĖĻĄ¼ņ¦æļŗ©ņŚÉņä£ ņ×¼Ēśä ļ░Å ļ│┤ļŗż ĻĘ£ļ¬©Ļ░Ć ĒÖĢņןļÉ£ ņŚ░ĻĄ¼ļōżņØ┤ ĒĢäņÜöĒĢśļŗż. ĻĘĖļ”¼Ļ│Ā ņØ┤ļ¤¼ĒĢ£ ņäĖļČĆ ļČäļźśĻ░Ć ļŗżņ¢æĒĢ£ ļŗ╣ļć©ļ│æņØś ĒĢ®ļ│æņ”ØĻ│╝ ņ╣śļŻīņŚÉ ņ¢┤ļ¢╗Ļ▓ī ĒÖ£ņÜ®ļÉĀ ņłś ņ׳ļŖöņ¦ĆņŚÉ ļīĆĒĢ┤ņä£ļÅä ņŚ░ĻĄ¼Ļ░Ć ĒĢäņÜöĒĢśļŗż.
Ļ▓░ļĪĀ
ņĄ£ĻĘ╝ ļŗ╣ļć©ļ│æņØś ņ£ĀņĀäņĀü ĻĖ░ļ░śņØä ļŹö Ļ╣ŖņØ┤ ņØ┤ĒĢ┤ĒĢ©ņŚÉ ļö░ļØ╝ ņĀĢļ░ĆņØśļŻīņØś ņ¦ĆĒÅēņäĀņØ┤ Ļ│äņåŹ ĒÖĢņןļÉśĻ│Ā ņ׳ļŗż. ņ£ĀņĀäņĀü ņŚ░ĻĄ¼ Ļ▓░Ļ│╝ņŚÉņä£ ņ×äņāü ņĀüņÜ®ņ£╝ļĪ£ņØś ņØ┤ ņŚ¼ņĀĢņØĆ ņ£ĀņĀäņ£äĒŚśņĀÉņłśļź╝ ĒåĄĒĢ┤ ļŗ╣ļć©ļ│æņØś ņśłņĖĪ, ņ¦äļŗ©, ļČäļźś, ņ╣śļŻīņŚÉ ļīĆĒĢ£ ņĀæĻĘ╝ ļ░®ņŗØņØä ņāłļĪŁĻ▓ī ĒĢĀ Ļ░ĆļŖźņä▒ņØ┤ ļåÆļŗż. ņ£ĀņĀäņĀü ĒåĄņ░░ļĀźņØä ĒåĄĒĢ®ĒĢ©ņ£╝ļĪ£ņŹ©, ņĀĢļ░ĆņØśļŻīļŖö ļŗ╣ļć©ļ│æ ĒÖśņ×ÉņŚÉĻ▓ī ļŹö Ļ░£ļ│äĒÖöļÉśĻ│Ā ĒÜ©Ļ│╝ņĀüņØĖ ņØśļŻīņØś ļ»Ėļלļź╝ ņĀ£ņŗ£ĒĢĀ Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆļÉ£ļŗż.
 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print